¿Te has preguntado como hacen aplicaciones como Netflix, Spotify, Uber y otras para manejar tanta información?. La respuesta está en los modelos de bases de datos y cuando utilizar cada uno.
👌 Este post es el comienzo de una serie sobre Modelos y Bases de Datos
Aprende la diferencia de los principales modelos de bases de datos y cuando debes utilizar uno, otro o ambos para aplicaciones tipo Netflix.
Es momento de aprender a crear, diseñar, administrar y trabajar con bases de datos en python desde cero partiendo de comprender la teoría que nos va a servir como sostén y los principios de almacenamiento y desarrollo que debemos respetar para utilizar correctamente cada modelo en nuestras aplicaciones.
Antes de comenzar, déjame dejarte en claro que la lectura de este post puede no ser muy sencilla de comprender. Pero te aseguro que si lo lees detenidamente e investigas por tu cuenta cada concepto o palabra que te suene extraña, saldrás con una muy buena introducción a bases de datos.
Este es el primer post donde he recopilado mucha información de diferentes fuentes. Es parte de una serie dentro del 3er módulo de Pythones «Desarrollo de aplicaciones», perteneciente al apartado de bases de datos.
Introducción a las bases de datos
La Wikipedia define una base de datos como:
Conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso.
Esta es una definición muy genérica, como te darás cuenta. Porque una biblioteca puede ser una base de datos, un álbum de fotos de tus vacaciones también, e incluso un museo. Pero en informática, una base de datos está definida de forma más concreta.
Te comparto múltiples definiciones:
Una base de datos es una colección de información organizada de forma que un software pueda seleccionar rápidamente los fragmentos de datos que necesite.
Una base de datos es un sistema de archivos electrónico.
Las bases de datos tradicionales se organizan por campos, registros y archivos.
Una base de datos es un conjunto de datos almacenados y organizados con el fin de facilitar su acceso y recuperación mediante el uso de un ordenador.
Una base de datos es una serie de datos organizados y relacionados entre sí, los cuales son recolectados y explotados por un software o sistema de información.
También es buena idea revisar post anteriores como:
⚠️ Recomiendo leer estos dos post si has venido sin conocimientos previos
Es buena idea que si lees primero mi post sobre datos estructurados y diccionarios porque te aporta contexto sobre «Datos, Información y Estructura» que bien sirven de apoyo para comprender mejor las bases de datos y los modelos tanto relacionales como no relacionales. Datos estructurados en Python y Diccionarios.
Trabajar con bases de datos implica saber realizar consultas a diferentes tipo y modelos de bases de datos incluso a veces en una misma aplicación.
Bien, ya que te ha quedado medianamente la definición, y te he puesto en contexto; es momento de preguntarnos ¿
Y para qué sirven?
Hasta un archivo Excel o una Imagen es, en sí, una base de datos. Todo son bases de datos.. Claro señor Sherman, todo son bases de datos, el mundo es una enorme base de datos.
Las bases de datos son el núcleo de la información y datos que manejen nuestras aplicaciones.
Por ejemplo, una base de datos podría tener datos de usuario/administradores y otra fichas/datos de películas (Netflix).
Sea lo que sea vayas a programar es necesario usar una base de datos, así sea en un script a veces para guardar la configuración.
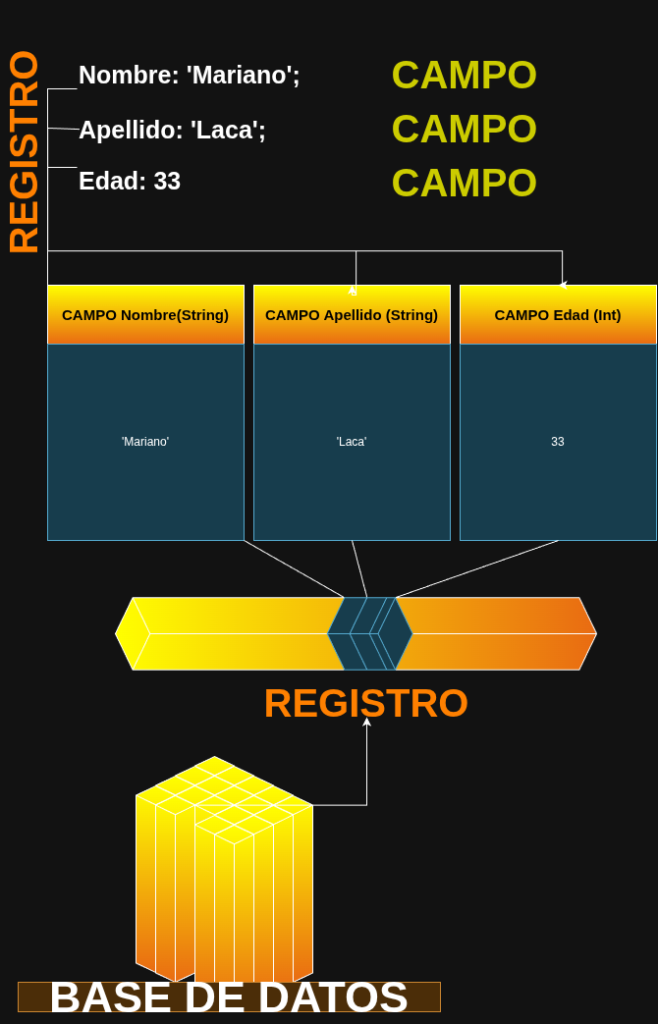
Campo, Registro y Archivo
Decimos que una base de datos se organiza en campos, registros y archivos:
Un campo es el área de almacenamiento que nos brinda la base de datos para guardar datos de un tipo específico (por ejemplo, datos de tipo entero). «Una caja donde guardas cosas que tiene un identificador.»
Un registro es una colección de datos iguales o relacionados, que pueden ser o no de tipos diferentes. «Varias cajas»
Un archivo es un conjunto de registros (datos relacionados de diferentes tipos ubicados en campos).»Un camión de mudanzas».
Así, un conjunto de archivos (cada uno es un conjunto de registros, y estos a su vez son un conjunto de campos relacionados y ordenados de diferentes tipos de datos) conforma una base de datos.
Para hacértelo más fácil, si no tienes ningún conocimiento de bases de datos, imagina que trabajas con un conjunto de archivos en Excel dentro de una carpeta, almacenando datos como en la imagen, y que existe un programa que hace «consultas» a esos ficheros para darte los datos que le pides.
«Si has trabajado con diccionarios en Python es bastante similar ya que los diccionarios son estructuras de datos par clave : valor que permiten ser anidadas.»
Concepto
Analogía
Definición Técnica
Campo
Caja individual con etiqueta
Almacena datos de un solo tipo
Registro
Grupo de cajas que van juntas
Conjunto de campos relacionados
Archivo
Estantería o camión de mudanzas
Conjunto de registros (tabla)
Base de Datos
El almacén completo
Conjunto de archivos interrelacionados
Características de las bases de datos
Nos permiten acceder y consultar los datos rápida y fácilmente.
Nos permiten almacenar enormes volúmenes de datos.
Permiten ser accedidas fácilmente por cualquier software o sistema.
Control de concurrencia: permiten que varios usuarios visualicen y modifiquen la información al mismo tiempo.
Proporcionan mecanismos de seguridad mediante usuarios, roles y contraseñas.
Control de redundancia: evitan la duplicación de datos (por ejemplo, tener un producto dos veces con diferentes precios, lo que sería un lío cuando alguien venga a comprar).
Clasificaciones de las bases de datos
Las bases de datos son muy útiles, y existen diversos tipos para diferentes propósitos. Aquí es donde se pone interesante: una base de datos puede clasificarse «según»:
Estáticas o dinámicas: Las bases de datos estáticas son de solo lectura, no se pueden modificar, solo consultar. Las bases de datos dinámicas permiten lectura y escritura a la vez: consultar, modificar y añadir datos.
Centralizadas o distribuidas: Podemos tener una base de datos en un único servidor, o una base de datos conformada por varias partes (particiones) alojadas en diferentes servidores o nodos en distintos puntos geográficos. La organización de bases de datos distribuidas es la más actual.
Clasificación por el teorema de CAP: Esta es una de las clasificaciones más importantes para quienes nos dedicamos al desarrollo de software, pues incluye el diseño y la elección del modelo de gestión de bases de datos. El teorema de CAP está enfocado a bases de datos distribuidas (múltiples bases de datos no alojadas en un solo nodo u ordenador/servidor). El teorema de CAP las clasifica:
Consistencia: Los datos deben «coincidir» en todos los nodos o servidores. Si tenemos múltiples bases de datos en diferentes servidores, los datos deben ser iguales; no puede haber diferentes valores para el precio de un mismo producto, por ejemplo.
Disponibilidad: Se debe poder seguir consultando o almacenando datos aunque alguno de los nodos no esté disponible.
Tolerancia a particiones: Permite que la base de datos esté particionada o dividida en diferentes nodos/servidores y funcione correctamente a pesar de ello.
Pero este teorema indica que en sistemas de bases de datos distribuidos no se pueden cumplir las tres características al mismo tiempo.
Por ello existen diversos modelos de almacenamiento y gestión que cumplen bien alguna de las características pero flaquean en otra. A continuación veremos estos modelos (relacional y no relacional), aunque existen más, y podrás entender la diferencia y en cuál de las tres características fallan pero como sacar provecho de cada una a la hora de desarrollar tus aplicaciones.
Te iré introduciendo poco a poco, contándote la historia y el nacimiento del modelo relacional.
Historia de bases de datos y el viejo Codd
Los anteojos los añadí yo porque le quedarían muy bien.
Para comprender mejor las cosas, es necesario contarte un poco de historia y darle su debido agradecimiento a una persona. De quien hablo es de Edgar Frank Codd. Entenderás por qué en un momento.
Primero, déjame contarte una historia que seguro tus padres o abuelos podrán confirmar.
Antes de que apareciera este tipo en los maravillosos años 70, la informática estaba en su despertar con la aparición de los ordenadores de uso doméstico. Eran unas máquinas enormes que apenas tenían unos pocos megas de RAM y eran más víctimas de golpes e insultos que de utilidad. Seguro recuerdas en la casa de la abuela o has visto una foto de estos enormes equipos.
Por aquella época estaban naciendo los lenguajes de programación y el almacenamiento era muy escaso. Un disco duro no era lo que es hoy (reducido tamaño físico y gran capacidad). Se trabajaba con cintas, y comenzaban a aparecer los discos flexibles (floppy disks) y otras tecnologías que pronto serán reliquias.
Sucedía que los programadores de entonces tenían «el libre albedrío» de programar y diseñar la gestión y almacenamiento de los datos como se les diera la gana. Los programas repartían la información en el disco duro en campos y registros dentro de ficheros, como si tuvieras 200 archivos de texto repartidos por todo el PC. Para relacionar un dato con otro se utilizaban punteros (direcciones físicas dentro de ficheros).
En esas épocas se recurría a los modelos jerárquicos (estructuras con relación padre-hijo que generaban mucha redundancia) y al posterior modelo de red (estructura de relación de todo con todo N:N que solucionaba la redundancia pero era extremadamente complejo).
Imagínate: cuando había que agregar nuevos datos, había que hacer lugar, recalcular punteros y lidiar con toda esa frustración en un lenguaje como Cobol.
Los programas se volvían cada vez más complejos, lentos y difíciles de mantener. Las empresas gastaban fortunas en programadores e ibuprofeno para sus dolores de cabeza. Era un auténtico caos.
En resumen:
La información se repartía en el disco duro en campos y registros dentro de ficheros que necesitaban de otros ficheros para establecer una relación.
Para representar la relación entre unos y otros se utilizaban punteros.
Había muchísimos ficheros por todo el disco, con información distribuida, mal organizada, insegura, atomizada (regada por todos lados) y con redundancia (los mismos datos almacenados en varios lugares).
Se gastaba mucho dinero y costaba mantener programas y administrar grandes cantidades de información.
Básicamente, en esas épocas no quieres imaginarte el dolor de cabeza de los pobres programadores.
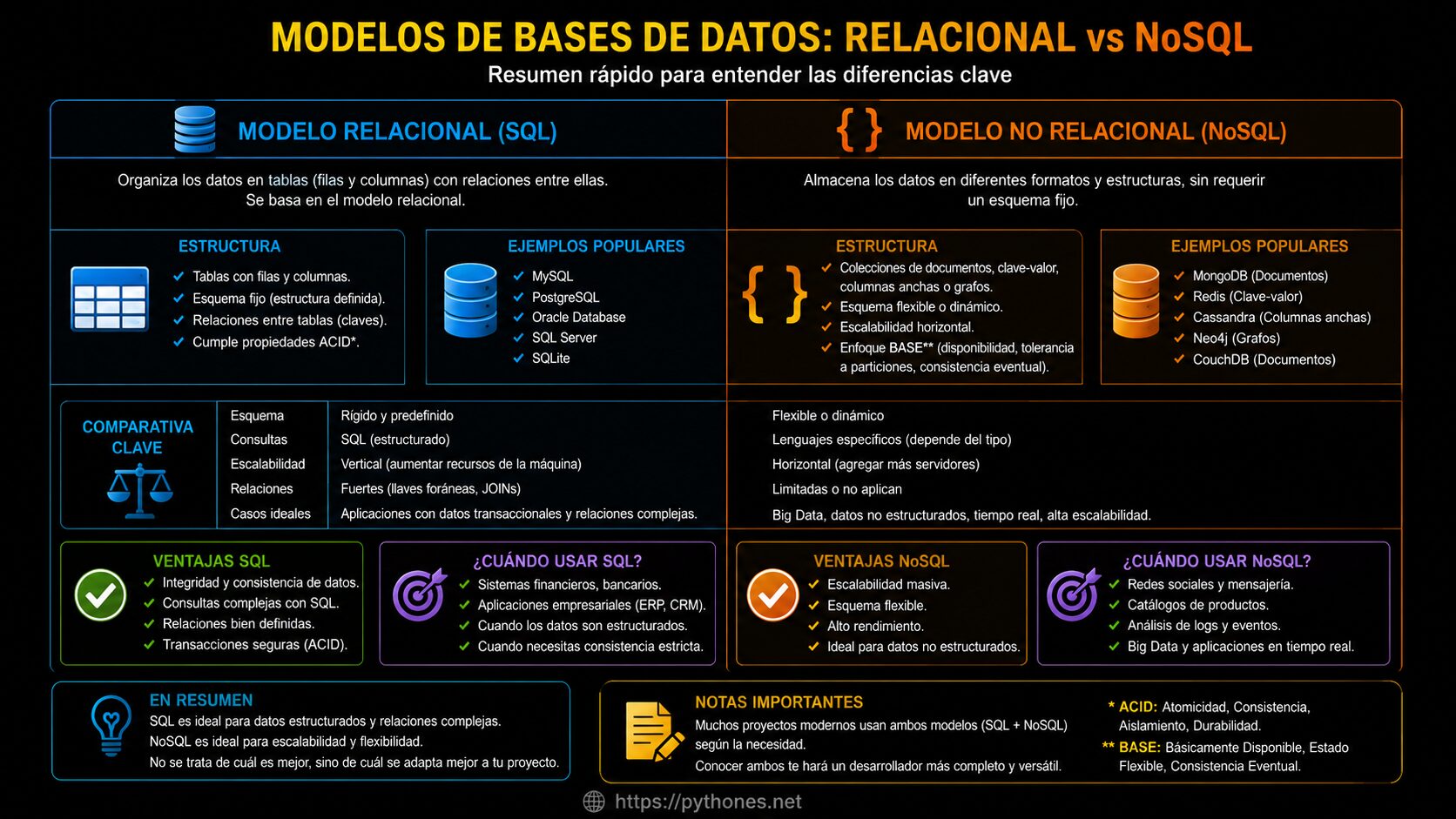
Modelos relacional vs no relacional
Aquí está lo que más interesa que entiendas sobre las bases de datos y los modelos para luego saber precisamente cual aplicar o aplicar ambas en tu aplicación pero de forma correcta, mantenible, escalable y organizada. Para que tus aplicaciones en un futuro jamás sean un caos, te presento aquí dos modelos:
Modelo relacional
Vino este tipo, Edgar Codd 😎, creador del modelo relacional en 1970, y dijo: «Ya basta de punteros y ficheros, vamos a hacerlo a mi modo». Se paró ante la mirada atenta de todos (me lo estoy inventando) y dijo a partir de ahora:
La relación entre una tabla padre y una hija se lleva a cabo mediante llaves primarias y llaves foráneas (o ajenas).
Las llaves primarias son la clave principal de un registro dentro de una tabla y deben cumplir con la integridad de datos.
Las llaves ajenas (foráneas) se colocan en la tabla hija, contienen el mismo valor que la llave primaria del registro padre; por medio de ellas se establecen las relaciones.
¡Y mientras respeten estas reglas siempre se irán a casa temprano!
Las bases del modelo relacional
Codd establece las bases del modelo relacional que utilizamos hoy, donde:
Reemplaza el uso de los punteros por «valores» que sirven como claves.
Ofrece representar la información como un conjunto de tablas.
El usuario ve y trabaja solo con tablas.
Se cuenta con un gestor del sistema de almacenamiento de datos que recibe órdenes a través de un lenguaje comprensible por el humano y no procedimental (SQL). Le dices lo que quieres y el sistema lo encuentra sin que tú tengas que escarbar manualmente en las tablas.
Separa la representación física de la lógica, ocultando la representación física de los datos.
Toda esta información se sirve desde un lugar centralizado, no distribuido como antes.
Beneficios de las bases de datos relacionales
Acceso más rápido a los datos.
A través de una base de datos unificada, la aplicación navega para responder a la solicitud del usuario.
Evita la duplicidad de registros.
Garantiza la integridad referencial: al eliminar un registro, se eliminan todos los registros relacionados dependientes.
Son más amigables, favorecen la realización de informes y optimizan tiempos y procesos.
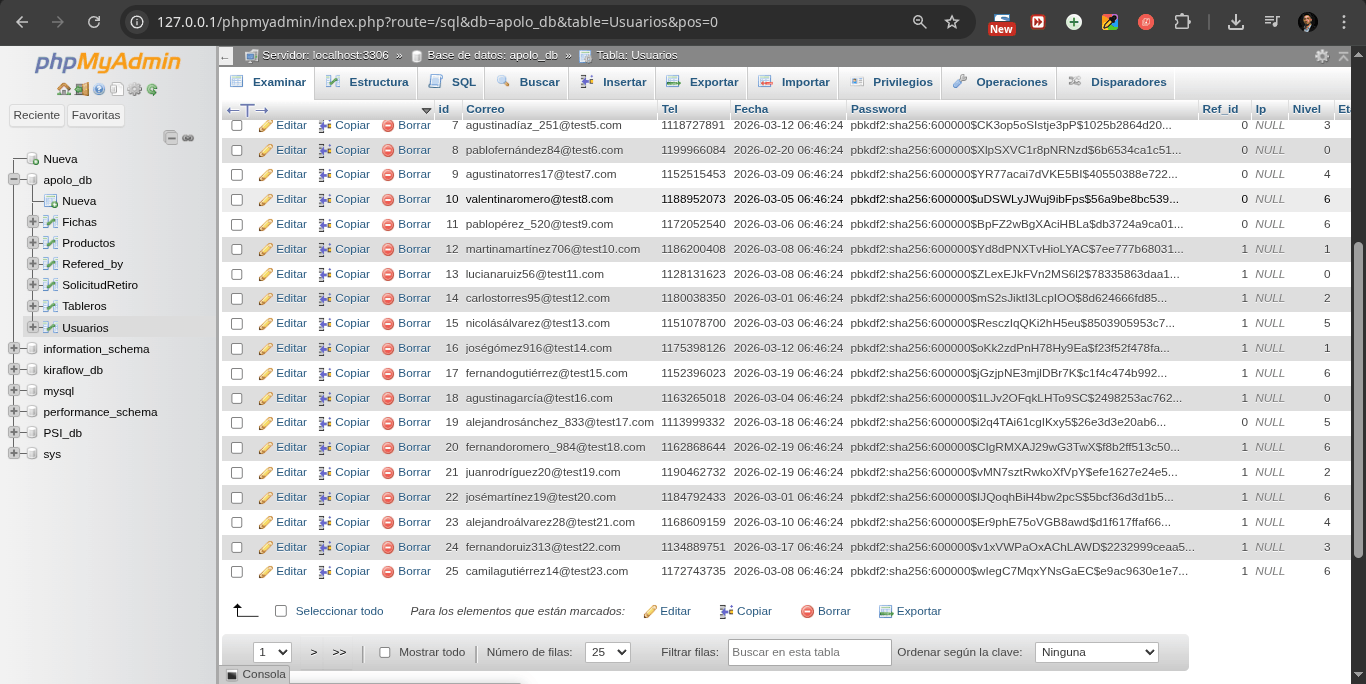
Así organiza los datos en tablas con campos organizados en columnas y filas (como un Excel), centralizadas en una base de datos. Algo así:
Esto es una tabla de una base de datos en MySQL vista desde phpMyAdmin. A la izquierda las bases de datos, a la derecha las tablas de la seleccionada, cada Tabla es un conjunto de Registros.
Puede parecer difícil de comprender al principio, pero verás que a medida que sigas leyendo estas entradas se hará cada vez más fácil y habrás adquirido el conocimiento más relevante a la hora de desarrollar correctamente tus modelos y bases de datos cuando trabajes con python.
Debes aprender a trabajar con ambos modelos, ya te explique el modelo «Relacional» ahora toca el «No Relacional» O NoSQL:
Modelo no relacional – NoSQL
Las bases de datos no relacionales, también conocidas hoy como bases de datos NoSQL (porque no utilizan SQL para consultas), utilizan variados modelos de datos para acceder y administrar la información.
Normalmente, este tipo de modelo está adaptado y optimizado para administrar un inmenso volumen de datos donde se requiere un acceso rápido y un modelo flexible.
(Con esto me refiero, a quiero que sea rápido, texto plano, y no depender de SQL para obtener datos de ella sino un modelo propio más liviano y adaptado a mis necesidades)
Utilizadas en numerosas aplicaciones móviles o videojuegos, las bases de datos no relacionales logran esta optimización flexibilizando algunas de las restricciones de coherencia de datos que tienen otras bases de datos.
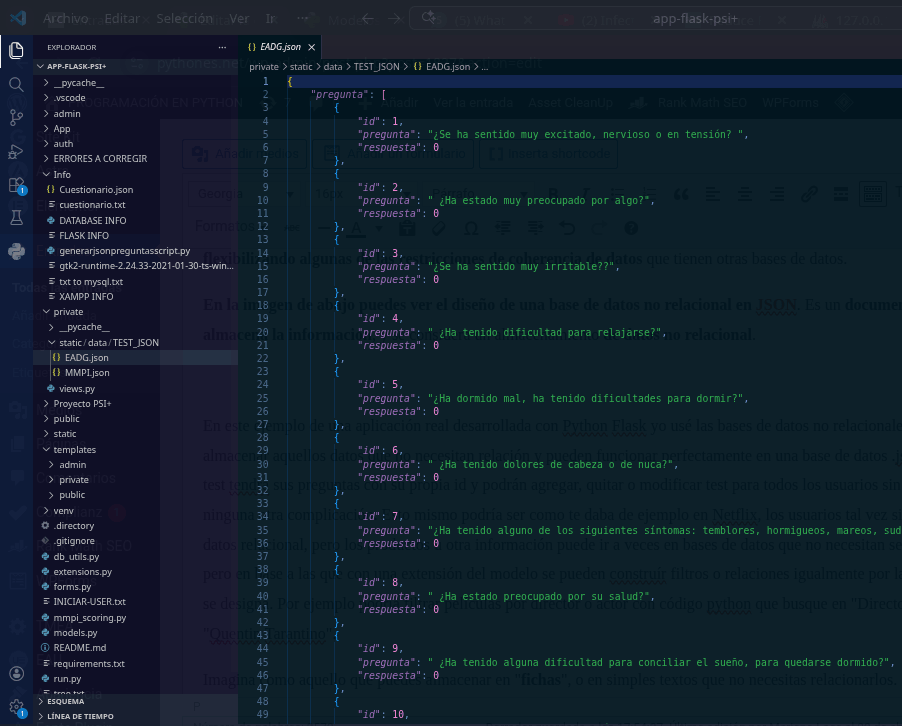
En la imagen de abajo puedes ver el diseño de una base de datos no relacional en JSON. Es un documento donde se almacena la información, y se considera un almacenamiento de datos no relacional.
En este ejemplo de una aplicación real desarrollada con Python Flask (PSI+ Psycological Software Inventary) yo usé las bases de datos no relacionales para almacenar aquellos datos que no necesitan relación y pueden funcionar perfectamente en una base de datos .json. Así cada test tendrá sus preguntas con su propia id y podrán agregar, quitar o modificar test para todos los usuarios sin necesidad de ninguna otra complicación.
Mira otro ejemplo de una base de datos de peliculas.json:
[
{
"id": 101,
"titulo": "El viaje de Chihiro",
"anio": 2001,
"director": "Hayao Miyazaki",
"duracion": 125,
"generos": ["Animación", "Fantasía"],
"sinopsis": "Una niña entra en un mundo mágico para salvar a sus padres.",
"puntuacion": 8.6,
"url_video": "https://cdn.ejemplo.com/chihiro.mp4",
"idiomas": ["japonés", "español"]
},
{
"id": 102,
"titulo": "Origen",
"anio": 2010,
"director": "Christopher Nolan",
"duracion": 148,
"generos": ["Ciencia ficción", "Acción"],
"sinopsis": "Un ladrón que roba secretos del subconsciente debe realizar la tarea inversa.",
"puntuacion": 8.8,
"url_video": "https://cdn.ejemplo.com/origen.mp4",
"idiomas": ["inglés", "español"]
},
{
"id": 103,
"titulo": "Superbad",
"anio": 2007,
"director": "Greg Mottola",
"duracion": 113,
"generos": ["Comedia"],
"sinopsis": "Dos adolescentes intentan perder su virginidad antes de graduarse.",
"puntuacion": 7.6,
"url_video": "https://cdn.ejemplo.com/superbad.mp4",
"idiomas": ["inglés", "español"]
}
]
Esto mismo podría ser como te daba de ejemplo en Netflix, los usuarios tal vez si una base de datos relacional como te mostré al principio MySQL, pero los productos u otra información puede ir a veces en bases de datos que no necesitan ser relacionales como JSON, pero en base a las que con una extensión del modelo se pueden construir filtros o relaciones igualmente por la estructura que se designa. Por ejemplo podría filtrar películas por director o actor con código python que busque en «director» el valor «Quentin Tarantino«.
Imagina como aquello que puedes almacenar en «fichas«, o en simples textos que no necesitas relacionarlos. Como un enorme archivador y lector scanner ultra veloz (modelo-controlador python).
Saber escoger, utilizar y diseñar la gestión de datos con ambos modelos te convertirá en una navaja suiza de los desarrolladores. No se trata de volver a los ficheros dispersos; el modelo no relacional también se ha actualizado y tiene mejores formas de trabajar.
Tipos de bases de datos (modelos no relacionales)
Clave-valor: modelo muy similar a los diccionarios. Utiliza el método simple de clave-valor para almacenar datos como un conjunto de pares donde la clave representa un valor único. Lo usan SnapChat, Netflix, Nike, etc. Puedes leer más sobre ellas aquí: Bases de datos clave-valor Amazon
Documentos: Como te mostré con JSON (JavaScript Object Notation). También entran aquí XML, MongoDB, etc. Consisten en documentos (ficheros) donde almacenamos de forma eficiente e intuitiva los datos, facilitando su almacenamiento y consulta. La naturaleza flexible, semiestructurada y jerárquica permite que evolucionen según las necesidades de las aplicaciones.
Gráficos: Permiten expresar relaciones y diferencias entre diferentes datos y tipos de datos, algo así como las estadísticas.
Otras: Existen más, como el almacenamiento en memoria caché, que no vienen al caso para no causarte pesadillas.
Beneficios de las bases de datos no relacionales
Los beneficios son variados, pero el que más me gusta destacar es la velocidad de consulta y la facilidad para añadir nuevos datos para el programador. También podemos ver aplicaciones que combinan ambos modelos para diferentes objetivos.
Las bases de datos NoSQL están diseñadas para varios patrones de acceso a datos. Las de búsqueda NoSQL están diseñadas para hacer análisis sobre datos semi-estructurados.
Proporcionan una variedad de modelos de datos para el desarrollador, a diferencia del modelo relacional que es casi único.
Permiten un escalado horizontal y admiten un amplio volumen de datos. Podemos almacenar más datos, más rápido, lo que mejora la latencia y el rendimiento.
Comparamos modelos relacional vs no relacional – ejemplo
Vamos a suponer que estamos creando una aplicación para que los usuarios puedan descargar PDF’S. Para los usuarios usaremos una base de datos Relacional y para los PDF’S usaremos una base de datos No Relacional JSON:
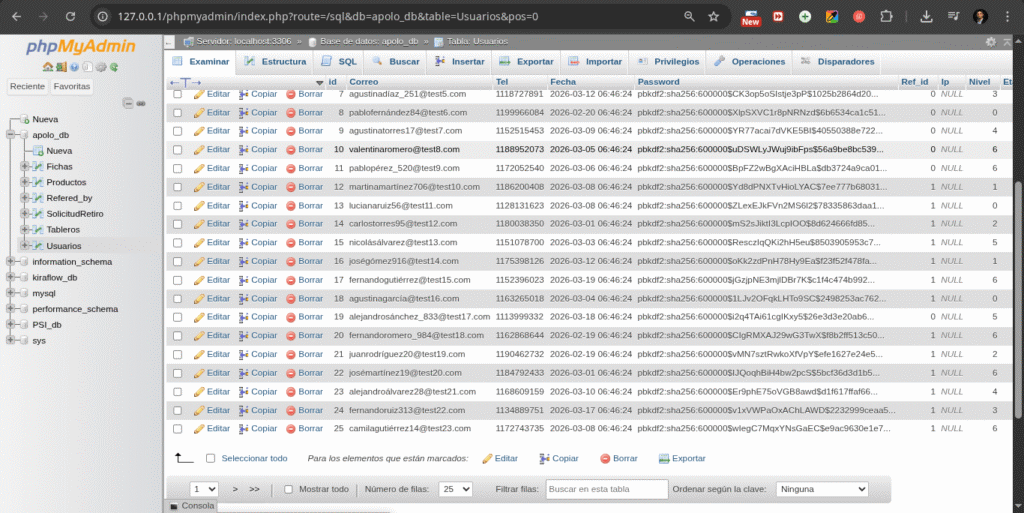
Ejemplo Usuarios en MySQL(Relacional)
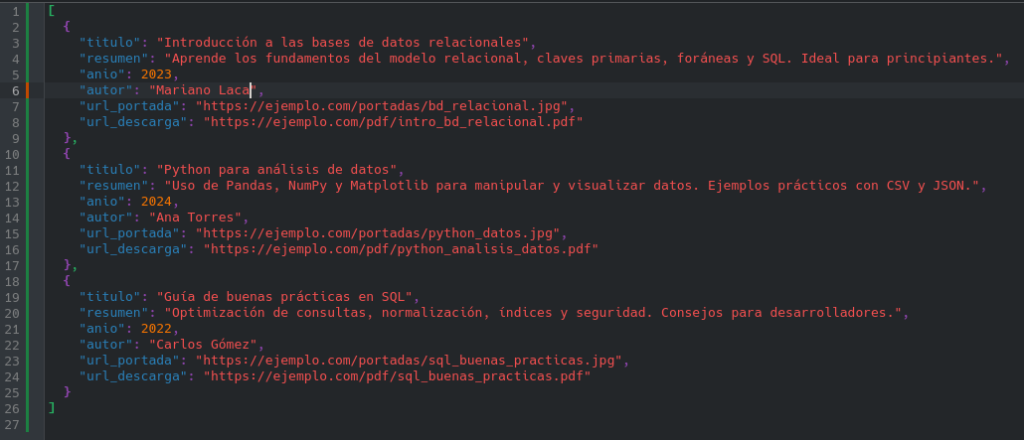
Ejemplo PDF JSON (No Relacional) con su Link de descarga e imagen de portada:
Entonces nuestra aplicación tendrá una base de datos relacional para el sistema usuarios y una no relacional donde almacenaremos los pdfs con sus datos (titulo, imagen de portada, link de descarga, etc.)
Es un ejemplo burdo pero práctico para que entiendas mejor.
📌 Resumen breve – Modelos de bases de datos
Una base de datos es un conjunto de información organizada para su rápido acceso, consulta y modificación. Los dos grandes modelos actuales son:
Relacional (SQL): organiza los datos en tablas relacionadas mediante claves primarias y foráneas. Ideal para datos estructurados, con relaciones complejas y que requieren integridad referencial.
No relacional (NoSQL): almacena datos en documentos, clave-valor, grafos o columnas. Perfecto para grandes volúmenes de datos semiestructurados, escalabilidad horizontal y esquemas flexibles.
La elección del modelo depende de las necesidades de tu aplicación: ¿necesitas relaciones estrictas y consultas complejas? → SQL. ¿Necesitas velocidad, escalabilidad y esquemas cambiantes? → NoSQL. Incluso puedes combinar ambos (arquitectura híbrida).
📊 Comparativa modelos de bases de datos (Relacional vs No relacional)
Siempre todo es más fácil de comprender desde una tabla o un diagrama, por eso puedes ver aquí una tabla comparativa entre ambos «modelos» de bases de datos.
Recordemos que en algunas aplicaciones y dependiendo los requerimientos de la misma podemos usar ambos modelos. Por ejemplo Modelo Relacional para gestión de usuarios, y JSON (No Relacional) para gestión de datos de artículos.
No hay un modelo «mejor» que otro. La clave está en conocer las fortalezas de cada uno y aplicarlas según el tipo de dato y la operación que necesites. En aplicaciones reales (como Netflix, Spotify o Uber) se usan ambos modelos en conjunto: SQL para usuarios, facturación y relaciones críticas; NoSQL para catálogos, logs, recomendaciones y datos de alta velocidad.
Bienvenidos a Aplicaciones Flask Web [Parte 3]: CRUD Completo. En esta tercera parte vamos a implementar todas las operaciones de gestión de datos (CRUD)…
Bienvenido a un nuevo post de mi blog sobre python flask; anteriormente vimos como funciona la arquitectura MVC, creamos un proyecto y aprendimos a crear…


 Aprende la diferencia de los principales modelos de bases de datos y cuando debes utilizar uno, otro o ambos para aplicaciones tipo Netflix.
Aprende la diferencia de los principales modelos de bases de datos y cuando debes utilizar uno, otro o ambos para aplicaciones tipo Netflix.


 Nos permiten almacenar enormes volúmenes de datos.
Nos permiten almacenar enormes volúmenes de datos. Nos permiten almacenar enormes volúmenes de datos.
Nos permiten almacenar enormes volúmenes de datos.
 Imagínate: cuando había que agregar nuevos datos, había que hacer lugar, recalcular punteros y lidiar con toda esa frustración en un lenguaje como Cobol.
Imagínate: cuando había que agregar nuevos datos, había que hacer lugar, recalcular punteros y lidiar con toda esa frustración en un lenguaje como Cobol.